There are two approaches to cash application automation that you’ll find in the marketplace: rule-based matching and confidence-based matching.
We’ll give you an exhaustive comparison later. But here at Billtrust, we emphasize the experience that our customers have with our software solutions along with our results – because we know you can’t get good results without an intuitive, flexible experience.
So, let’s start where the human experience of cash application begins: exception handling.
Matching is automated, exceptions are human-driven
For cash application solutions, automatically matching the majority of payments to invoices are the table stakes. But exceptions will always happen. Payment and invoice data is messy. Inconsistencies, mistakes and unexpected data is normal.
When an exception is identified, it’s up to humans to make the right match and then improve the automation so that there are fewer exceptions in the future.
Let’s look at a simple exception:
You have a customer who you are billing as Fairchild Tires, but they are paying your bills from their parent company, Fairchild Automotive.
This would be no problem for a human. But an automated system will flag the difference in the names and log an exception.
The next step is for a human to enter the exception handling workflow and match the Fairchild Automotive payment to the Fairchild Tires Invoice.

This is where confidence-based matching and rule-based matching diverge.
In a rule-based engine, the next time Fairchild Automotive pays a Fairchild Tires invoice another exception will be generated. And this could go on forever. The system will never learn because it’s programmed to follow pre-set rules. The only way to teach it that Fairchild Automotive is the same as Fairchild Tires is to add a rule for this exception which requires additional development work and associated costs.
In a confidence-based engine, once a human manually matches the payment to the invoice, you will never see this exception again. The confidence-based matching engine has learned from your behavior.
Let’s break this example down further. In a rule-based engine you might have a rule that states: PAYEE NAME ON PAYMENT must match PAYEE NAME ON INVOICE exactly. So even a small variation, like the difference between Fairchild Tire and Fairchild Tires would result in an exception.
Confidence-based engines work differently. There are rules, just like rule-based engines, but those rules are weighted. In a confidence-based engine, a rule might state: the more exactly that a payee name matches an invoice name, the higher the confidence we have of a correct match.
Here's an illustration:

A confidence-based matching engine takes into account confidence scores across many different categories, like our above example of the Name Likeness Score. With all other scores being equal, a confidence-based matching engine would more likely match an invoice and payment with only a small discrepancy between the payee names.
Confidence-based matching engines combine their confidence scores across all of the categories that they measure and average them into a Match Score. If that Match Score is over a certain threshold, the match happens.
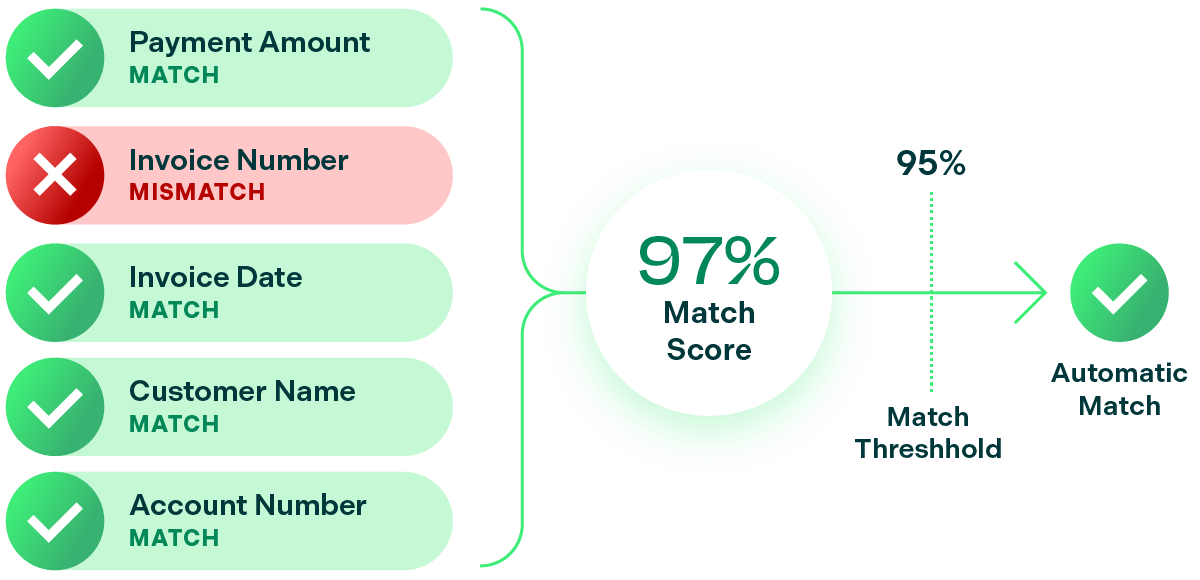
Here’s how a confidence-based matching engine learns from your exception handling behavior:
One of the categories that contributes to the Match Score is past history. If a user has manually matched a Fairchild Tire invoice to a Fairchild Automotive payment in the past, the engine will use that information to boost the Match Score. If a user had made that match multiple times – it’ll boost the Match Score even higher! Soon, it’ll be over the threshold that results in an automatic match and that specific exception will never occur again.
Contrast that with a rule-based engine that will create an exception over and over again forever. The only way to stop the exception from occurring is by hiring a developer to write a new rule. Imagine doing this for every exception that occurs as new customers are added and as customer businesses are restructured.
A confidence-based engine improves itself by incorporating data gathered from exception handlers.
The power to go deep
Confidence-based matching engines give users control. And it goes beyond learning from your behavior. You can easily modify the weighting that each category has in the overall confidence score. And you can also raise or lower the threshold required to make a match based on your observations of exceptions being flagged by the system.
All exceptions will come with tentative matches made by the engine. If you observe that your current confidence score threshold for a match is 90%, but there are many exceptions with correct tentative matches scored at 88%, the threshold can be easily lowered.
Confidence-based matching is designed to work well with messy data. That’s why it’s perfect for cash application.
Rule-based matching works best with enormous, accurate and consistent datasets. It’s not as effective for cash application. And it ends up being more expensive to implement because changes require expensive time with developers.
Head-to-head comparison of rule-based and confidence-based matching engines
| Rule-based matching | Confidence-based matching | |
|---|---|---|
| Making changes to matching rules | Optimization can be slow and expensive because every change requires a developer. Can lead to a situation where AR teams accept a sub-optimal configuration. | Self-service capabilities allow changes to be made in minutes, not days. Most critically, rules can be easily added after implementation. |
| Optimizing match rates | Requires the intervention of a developer, either a contractor hired by the AR team, or someone from the solution provider. | Self-service and machine learning power constant evolution in the matching engine, ensuring that it is always moving towards its most optimal state. |
| New customer setup | Requires new rules to be written and developers to do so. |
New customers can be onboarded with simple self-service changes and machine learning optimization. |
| Complex relationships | Complex parent / child relationships amid customers can require custom rules be written for each relationship. |
Even if names and customer numbers differ, other elements that the matching engine looks for can still lead to correct matches without custom programing. And exception handling activities automatically improve that engine's recognition of parent / child relationships. |
| Ease of exception handling | Exceptions may be organized by rules they have violated, but they will not show suggested matches. |
Every unmatched invoice and payment is still assigned a Match Score. If it’s in the exception que, then the Match Score isn’t above the confidence threshold for an automatic match. But it will still suggest the best match, which can make exception handling easier. |
Machine learning is unleashed in confidence-based matching engines
The biggest benefit of confidence-based matching engines is that they enable machine learning to automatically improve matching. Rule-based engines don’t have the flexibility to add machine learning to the mix.
Learn more
We’ve gone deep into the topic of confidence-based versus rule-based cash application and you now understand the key differences between the two types of matching engines.
But we want to show you how Billtrust Cash Application, with its confidence-based and machine learning powered matching engine, can be customized to your specific situation and save you time and money.
Please reach out to our sales team and we’ll set a quick call with a cash application expert.